
任务编排
利用模板和策略模式将项目初始化行为进行封装,只需实现接口即可,统一管理执行动作和顺序。在Spring容器启动完成后按order顺序执行初始化任务(如缓存预热、配置加载),确保初始化操作的可控性和可维护性。
模板方法模式 定义InitialHandler接口,包含 层级type、同层级顺序order、初始化方法执行函数excuteInit
策略模式 实现 对应spring不同启动阶段的抽象类,不需要关注触发机制和事件监听
实现抽象类执行引擎abstractExcutor,定义excute方法,通过spi机制获取InitialHandler的Bean
stream流
筛选(与执行器相同type的Handler)
排序 order字段
执行 调用executeInit方法
不同策略的excutor继承抽象类,并根据spring规定的定义范式写代码即可
对修改关闭,对扩展开放。 如果需要新增一个初始化任务,只需要新增一个类继承对应的 Handler 即可,完全不需要修改现有的启动代码,极大地提高了系统的可维护性。
树形编排框架
利用组合模式和树形结构设计验证基础组件,实现统一管理复杂的业务验证逻辑。将购票前的多个验证环节(库存验证、用户资格验证、场次验证等)组装成树形结构,支持灵活的验证规则组合和复用,符合开闭原则。
树形动态编排框架
每个组件继承组件抽象类,定义组件的执行方法
继承Initial在spring初始化时,构建组件树(根据每个组件的type、层级、order)
tips:通过Java 泛型(Generics) 和 继承(Inheritance) 的机制定义组件树每个节点。
container存储每个组件树的根节点,container.execute( 业务type,业务param 例如 UserRegisterDto)
根据type获取组件树根节点,执行层序遍历依次执行组件
顶层父类定义泛型 AbstractComposite.java:
// T 是一个泛型占位符
public abstract class AbstractComposite<T> {
// 定义了一个抽象方法,参数类型是 T
protected abstract void execute(T param);
}
此时,execute 方法接受什么参数主要取决于 T 是什么。
2. 中间类确定泛型类型
查看 AbstractUserRegisterCheckHandler.java:
// 这里明确指定了 T = UserRegisterDto
public abstract class AbstractUserRegisterCheckHandler extends AbstractComposite<UserRegisterDto> {
}
因为这里继承时写了 <UserRegisterDto>,所以对于这个类及其子类来说,父类中的 T 就被替换成了实际的类 UserRegisterDto。
此时,父类抽象方法签名的约束就变成了: protected abstract void execute(UserRegisterDto param);
UserExistCheckHandler.java:
public class UserExistCheckHandler extends AbstractUserRegisterCheckHandler {
// 必须实现父类的方法,此时参数类型已被锁定为 UserRegisterDto
@Override
public void execute(final UserRegisterDto userRegisterDto) {
// 所以在这里可以直接拿到 UserRegisterDto 对象使用
userService.doExist(userRegisterDto.getMobile());
}
}基因法
● 解决订单和用户ID双维查询的读扩散问题,设计基因标识策略,在零新增存储成本的前提下,支持不同维度的分库分表查询,降低数据延迟与维护成本。
分片键结合 分片算法决定数据存储位置
选择分片键的核心原则:分析业务场景和数据分布
1 高频查询,业务场景中的多数查询 都依赖于该字段,避免扫描所有分片
2 数据均匀,分片键的值应当离散分布,防止数据倾斜
目的:如果分片键字段的值 是相同的 多个行记录 可以存到同一个表/库中,提高查询性能
针对于订单数据分片键可以选择:卖家ID、用户ID、订单ID
需要分析业务场景和数据分布
1业务场景:
a最高频的场景是 用户去查询自己的订单
b其次是商家去查看自己售卖的订单
2数据分布:
a天猫、苏宁易购等商家的 订单量非常多,占整个数据集的比重很大,而小商家订单量少
具体分析:
●如果选择卖家ID为分片键
○第一,天猫的订单(数据量很大)都会被分到同一张表或数据库,造成数据倾斜
○第二,最高频的场景,用户查看自己的订单,结果a订单在A表/库,b订单在B表/库,此时需要多表/库扫描才能得到用户的订单集合,性能比较低
●如果选择订单ID为分片键
○虽然不会存在数据倾斜,但是仍然是没有考虑到用户查看自己订单这样一个最高频的场景,仍然需要多表/库扫描才能得到用户的订单集合,性能比较低
●如果选择用户ID为分片键
○第一,不可能有一个用户买了很多很多商品,以致于数据倾斜,因此数据分布是均匀的
○第二,符合业务的最高频场景,当用户查看自己的订单时,由于同一个用户ID的订单都会被分到同一张表/一个库,因此只需要去这一张表/库中查询,性能高
所以应该选择以用户ID为分片键
● 优化订单超时关闭任务,基于Redisson延迟队列,利用分片思想结合线程池,将消息处理延迟从250ms优化至100ms以内。
● 解决分布式链路透传trace_id丢失问题,实现链路追踪、日志、指标的可视化监控,将问题平均定位时间缩短至分钟级。
利用模板和装饰者模式对线程池进行封装定制,利用TransmittableThreadLocal原理进行优化,使其能够支持MDC和ThreadLocal中的数据传递,分布式链路ID也能够正常传递。解决了线程池场景下上下文丢失问题,保证了日志完整性和链路可追踪性。
1. 问题背景与选型思考 在微服务架构中,一个用户请求往往涉及几十个服务调用。一旦出现问题,如果没有一个能够串联全链路的标识,排查故障将非常困难。 虽然像 SkyWalking 这样的 APM 工具功能强大,但其实际原理基于字节码增强,需要在本地内存汇总数据并通过 gRPC 传输,对 CPU 和内存有一定开销。对于只需要核心链路追踪功能的场景,直接引入 SkyWalking 略显“杀鸡用牛刀”。 因此,为了在保证性能低损耗的前提下实现请求流程跟踪、故障定位和日志审计,我们决定自研一套轻量级的分布式链路ID方案。
2. 核心设计思路 我们的设计遵循以下几个原则:
- 唯一性:结合 UUID 或 Snowflake 算法生成全局唯一的 TraceID。
- 无侵入传播:利用 HTTP Header 在服务间传递,利用 ThreadLocal 在服务内部传递。
- 日志集成:将 TraceID 注入到 SLF4J 的 MDC(Mapped Diagnostic Context)中,配置 Logback/Log4j2 自动在每行日志中打印 ID,无需修改业务代码。
3. 关键实现细节
网关层生成: 链路ID的生成源头在网关(Nginx 或 Gateway)。当请求到达网关时,生成一个 TraceID 并放入请求头(Header)中,随后透传给后端服务。
服务内日志透传: 在每个微服务中,通过实现一个 Web 过滤器(Filter/Interceptor),从请求头中获取 TraceID,放入 MDC。这样,该请求后续产生的所有日志都会自动带上这个 ID。
Feign 远程调用传递: 由于 Feign 默认不会透传 Header,我们通过实现
RequestInterceptor接口,在发送请求前拦截,从当前线程的RequestContextHolder获取 TraceID,并手动添加到下游服务的请求头中,确保链路不断裂。
4. 难点解决:多线程与线程池环境下的上下文传递
这是实现过程中最大的挑战。Request 和 MDC 的底层都是基于 ThreadLocal 实现的,而 ThreadLocal 是线程隔离的。当业务逻辑进入线程池执行异步任务时,子线程无法访问主线程的 ThreadLocal 数据,导致链路ID丢失。
常见误区: 网上常见的做法是使用
InheritableThreadLocal或者手动在子线程中设置 RequestAttributes。但这在线程池场景下有严重隐患:线程池的线程是复用的,InheritableThreadLocal只有在线程创建时才会拷贝数据,后续复用时数据不会更新,导致“串号”或数据丢失。此外,父线程如果提前结束清理了上下文,子线程也会读取失败。我的解决方案(亮点): 虽然可以使用阿里的
TransmittableThreadLocal (TTL),但引入外部依赖略显笨重。我选择对线程池进行轻量级定制封装:- 装饰器模式:自定义一个任务包装类(Runnable/Callable Wrapper)。
- 捕获(Capture):在任务提交(submit/execute)的瞬间,在主线程中捕获当前的 TraceID(或 MDC 上下文)。
- 回放(Replay):在任务执行(run)的开始,将捕获的 TraceID 设置到子线程的
ThreadLocal/MDC中。 - 恢复(Restore):在任务执行结束后,清理子线程的上下文,防止污染下一次任务。
5. 总结 通过这套方案,我们在几乎不影响系统性能的前提下,实现了全链路日志的串联。无论是在 Kibana 中排查日志,还是进行简单的链路分析,效率都得到了极大的提升。同时,自定义线程池传递上下文的方案,也避免了引入重型框架的复杂性。
高并发流量节目购票场景,涵盖节目管理、座位选座、订单交易等核心业务。
● 针对热门节目数据的缓存穿透问题,使用多级缓存和竞争回源策略,确保数据库在极端场景下的可用性。
- 引入本地缓存Caffeine进一步缓解Redis访问压力,并利用演出时间来设计数据淘汰策略,解决了内存压力过大的问题。通过Caffeine+Redis+数据库的三级缓存架构,并根据演出时间动态调整缓存过期时间,在保证数据时效性的同时最大化了缓存命中率。
- 通过使用读写锁、双重检测机制、多级缓存,引入"先查询,后加锁"的方案,解决缓存击穿问题。在热点数据失效时,通过读写锁控制只有一个线程去加载数据,其他线程等待或从多级缓存获取,避免大量请求直接打到数据库。
如何应对突发性热点数据暴增导致系统压力过大问题?Redis性能真的足够吗?百万并发的终极杀招 "多级缓存"如何确保多级缓存的一致性?
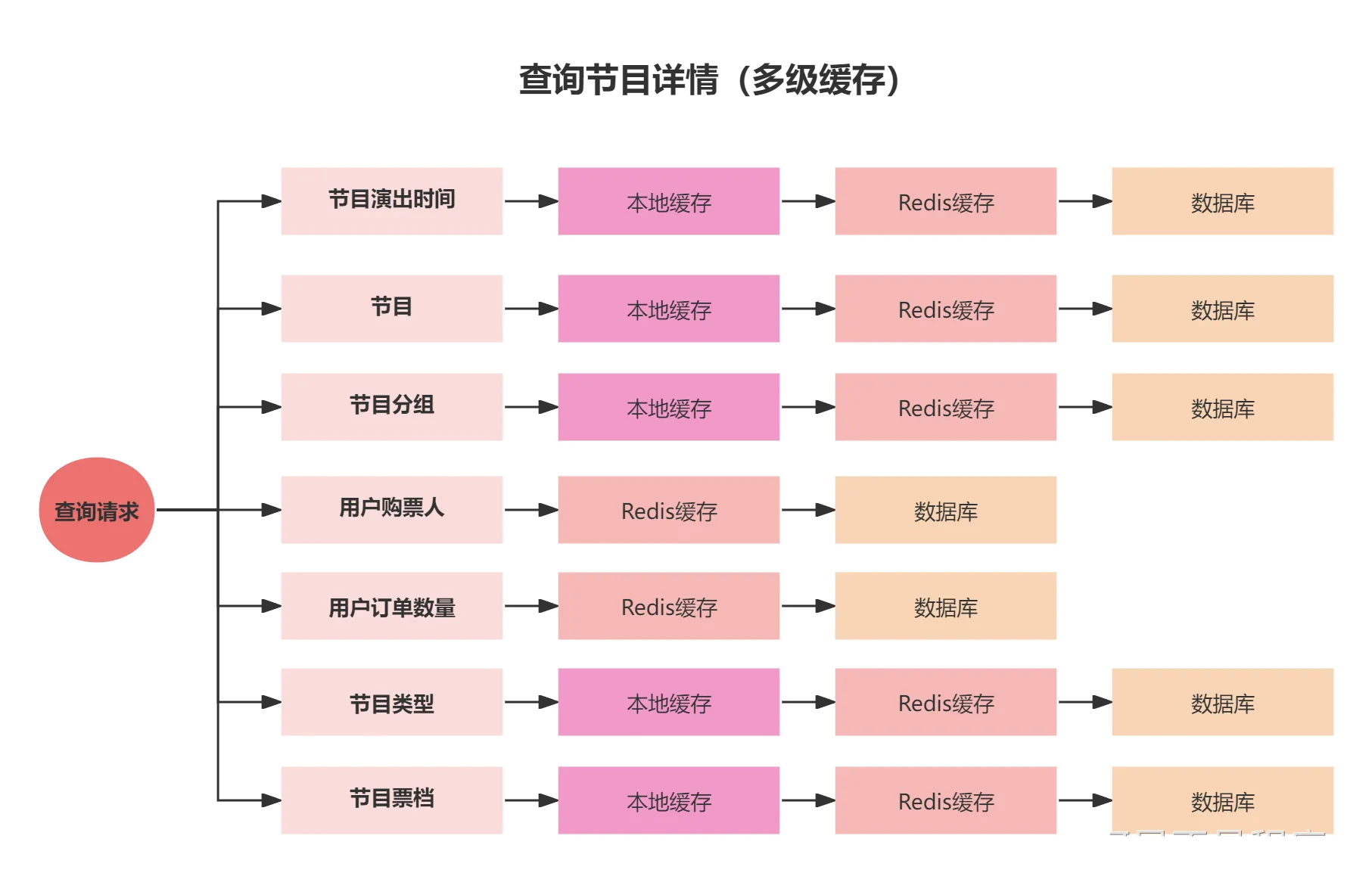
● 解决热点节目数据失效导致的缓存击穿,使用读写锁、双重检测机制、多级缓存组合策略,确保数据库在极端场景下的可用性,并利用RedisStream广播消息实现多级缓存最终一致性。
● 针对高并发购票请求下分布式锁网络瓶颈问题,设计本地实例锁+分布式锁策略,拆分座位图Redis键值对,实现无锁化扣减策略,结合Kafka完成异步订单创建,提升26%吞吐量。
- 通过Lua+Redis操作结合Kafka中间件进行异步创建订单,吞吐量提升了26%,并且可以保证不会出现余票超卖的问题。通过将同步的订单创建改为异步处理,释放了主流程的压力,同时通过Lua脚本保证了库存扣减的原子性。
● 利用策略模式与工厂模式实现业务逻辑的无侵入加锁,并提供多种锁类型。依据AOP执行链原理,解决了高并发下数据库事务提交与锁释放时序冲突导致的数据不一致问题。
● 针对注解式锁粒度过粗的问题,利用命令模式实现了基于函数式编程的分布式锁工具类,实现了锁生命周期的自动化管理,规避了手动释放锁可能引发的死锁风险,并支持多样化的锁超时降级策略。
学术
负责多层级、合并层级对比学习模型编码设计和优化,完成模块消融、超参灵敏度分析实验设计与结果分析。